I recently found an old RX 580 of mine and got the idea to build an accelerated database. I’m going into this completely blind, having no experience with parallel computing, and will be typing this as I progress. I want this devlog to be a bit more ‘docs-like’ so the tone in this series won’t be as conversational as my other posts, but instead a bit more formal. I’d also like to preface that most of my notes for this post came directly from Josh Holloway’s Intro to CUDA series on YouTube. Without further ado, the project.
Naturally, my first question was “How would I code on this thing?” and of course, it had to be plugged in. My motherboard did come with two GPU slots, but I only have a 750W power supply with an already plugged in 3070 (that requires 650W minimum), and I didn’t have any extra cords to power the RX 580, so I opted to use the 3070 instead. This revealed to be a good thing as I’d now be working with CUDA as opposed to AMD’s ROCm, which doesn’t have nearly as many resources, but that’s for later. Now, the question is “Why would I code on this thing?”, and to answer this I need an understanding of GPUs.
GPU?
Graphics Processing Units or GPUs are specialized for compute-intensive and highly parallel work, like rendering graphics. Because of this, it is designed in a way that more transistors (really small devices that control the flow of electricity) are devoted to processing rather than data caching. I couldn’t find anything specific about data processing/caching transistors, but the general idea is that “data processing” transistors are densely packed into clusters to perform mathematical operations (think ALU), and “data caching” transistors are organized into rigid, highly predictable grids. Central Processing Units or CPUs actually dedicate a large portion of its chip to these “data caching” transistors so it doesn’t have to wait for the RAM to send its information over.
CPUs are designed to minimize latency as majority of its real estate (on the CPU itself) belong to the advanced control logic and cache. GPUs on the other hand, are designed to maximize throughput as majority of its real estate is dedicated to the number of ALUs or, as Nvidia calls them, CUDA cores. While CUDA cores aren’t as complex as CPU cores, they come in numbers; my 3070, for example, comes with 5,888 CUDA cores.
To properly use the large number of CUDA cores, programs must decompose/break down their computations (that can be parallelized) into a large number of threads that can run concurrently. Each thread should do a small amount of work, and mostly run independently. Think of the CPU with its 4-16 cores as a company that’s recruited 4-16 specialized geniuses to work on very complex tasks, and the GPU with its 5,000+ cores as a factory line with 5,000+ very disciplined workers that do the same thing at the same time.
Organization of Threads
In CUDA, these threads are defined by special functions called kernels, which are executed on the GPU. When you launch a kernel, it is executed as a set of threads, each of them bound to a single CUDA core on the GPU. CUDA threads execute in a Single Instruction Multiple Thread fashion according to Nvidia, where threads are similar to data-parallel tasks. Each thread performs the same operation on a subset of data, and they execute independently. It’s a bit easier to understand if you can visualize it.
Kernels execute as a set of threads, and each thread is mapped to one CUDA core.

Blocks are groups of threads, and are mapped onto corresponding sets of CUDA cores.

Grids are groups of blocks, and are mapped onto the entire GPU and its memory. Each kernel launch creates a single grid.
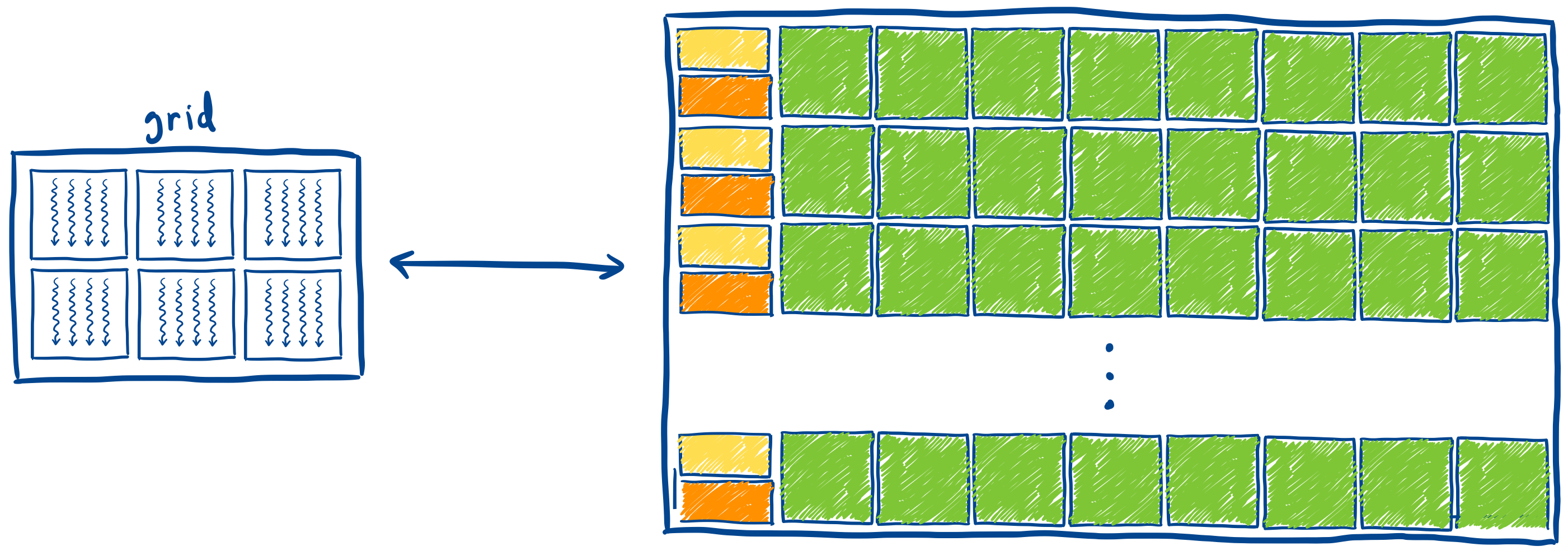
This is the very basic idea of what we’ll be utilizing within the GPU, and I plan to go further into technical depth as we progress with the project.
Until then.